
The article contains a brief introduction to Vision Transformers(ViT) in Deep Learning.

Introduction
This article is about most presumably the next generation of neural networks for all computer vision applications: The transformer architecture. You’ve definitely already heard about this architecture in the field of natural language processing(NLP) as illustrated by language models such as BERT and GPT-3. By contrast, the typical image processing system utilizes a convolutional neural network (CNN). So In this article, we'll understand how the transformer architecture be used in solving problems in the field of computer vision.
In 2022, the Vision Transformer (ViT) emerged as a competitive alternative to convolutional neural networks (CNNs) that are currently state-of-the-art in computer vision and therefore widely used in different image recognition tasks. ViT models surpassed the current state-of-the-art (CNN) by almost x4 in terms of computational efficiency and accuracy.
Vision Transformer(ViT)
Transformers calculate the relationships between pairs of input tokens (words in the case of text strings), termed attention. The cost is exponential with the number of tokens. For images, the basic unit of analysis is the pixel. However, computing relationships for every pixel pair in a typical image is prohibitive in terms of memory and computation. Instead, The Vision Transformer or ViT computes relationships among pixels in various small sections of the image (e.g., 16x16 pixels), at a drastically reduced cost. An image is split into fixed-size sections or patches, each of them is then linearly embedded, position embeddings are added, Each section is arranged into a linear sequence and multiplied by the embedding matrix, and the resulting sequence of vectors is fed to a standard Transformer encoder. Image sections are treated the same way as tokens (words) in an NLP application.
ViT was introduced in a research paper published as a conference paper at ICLR 2021 titled “An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale”. It was developed and published by Neil Houlsby, Alexey Dosovitskiy, and 10 more authors of the Google Research Brain Team.
The fine-tuning code and pre-trained ViT models are available on the GitHub of Google Research. You can find them here. The ViT models were pre-trained on the ImageNet and ImageNet-21k datasets.
The Architecture of the Vision Transformer
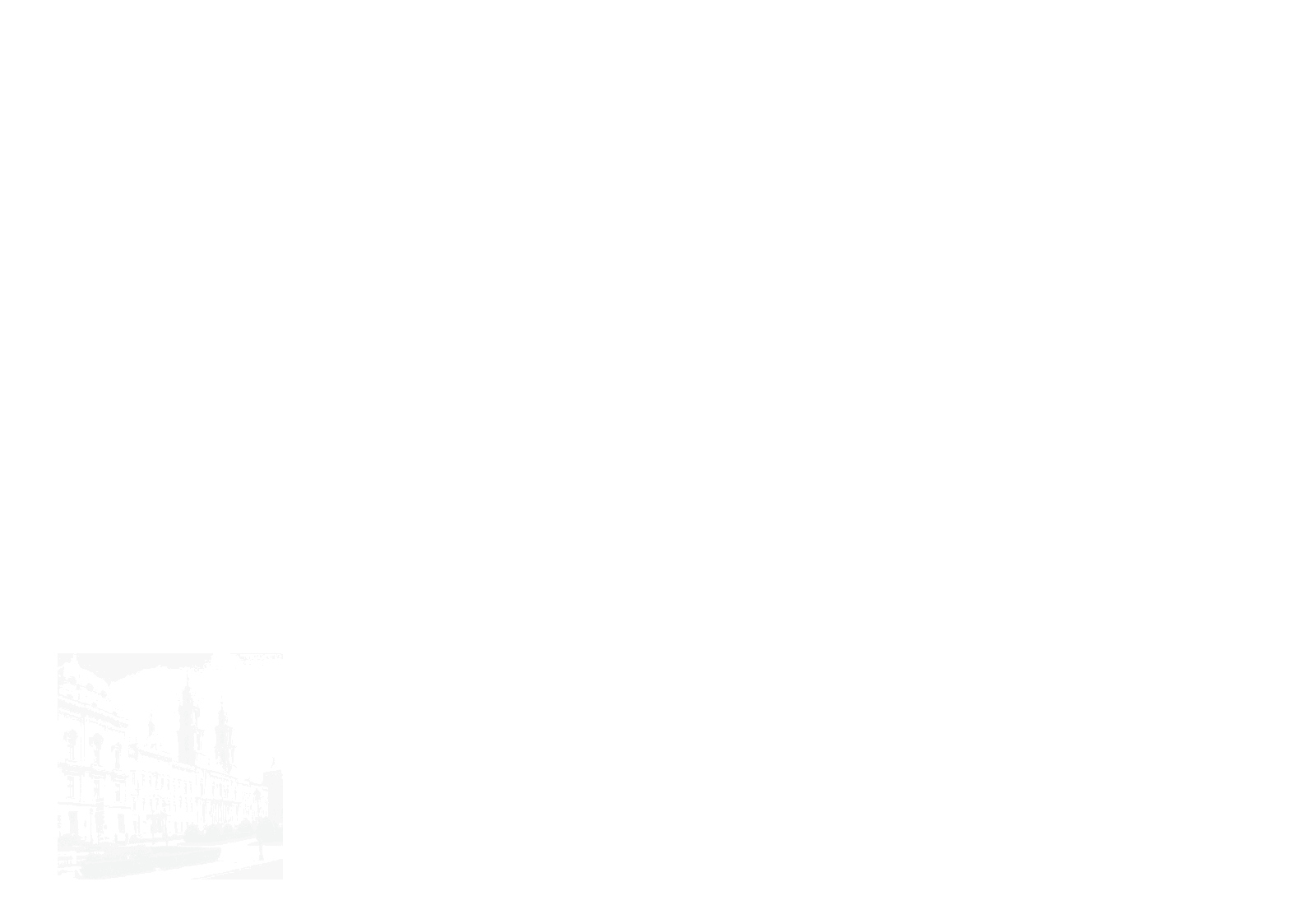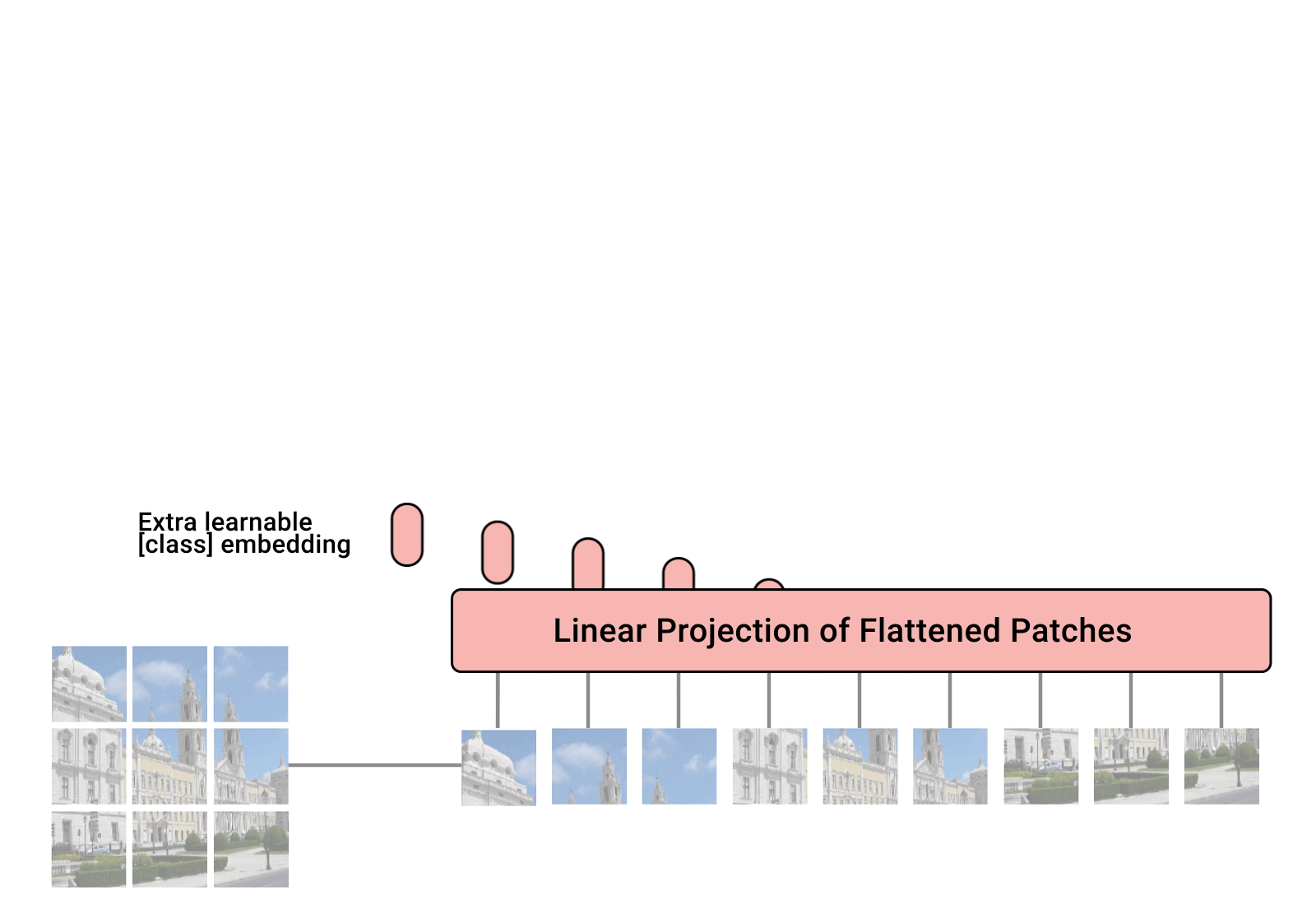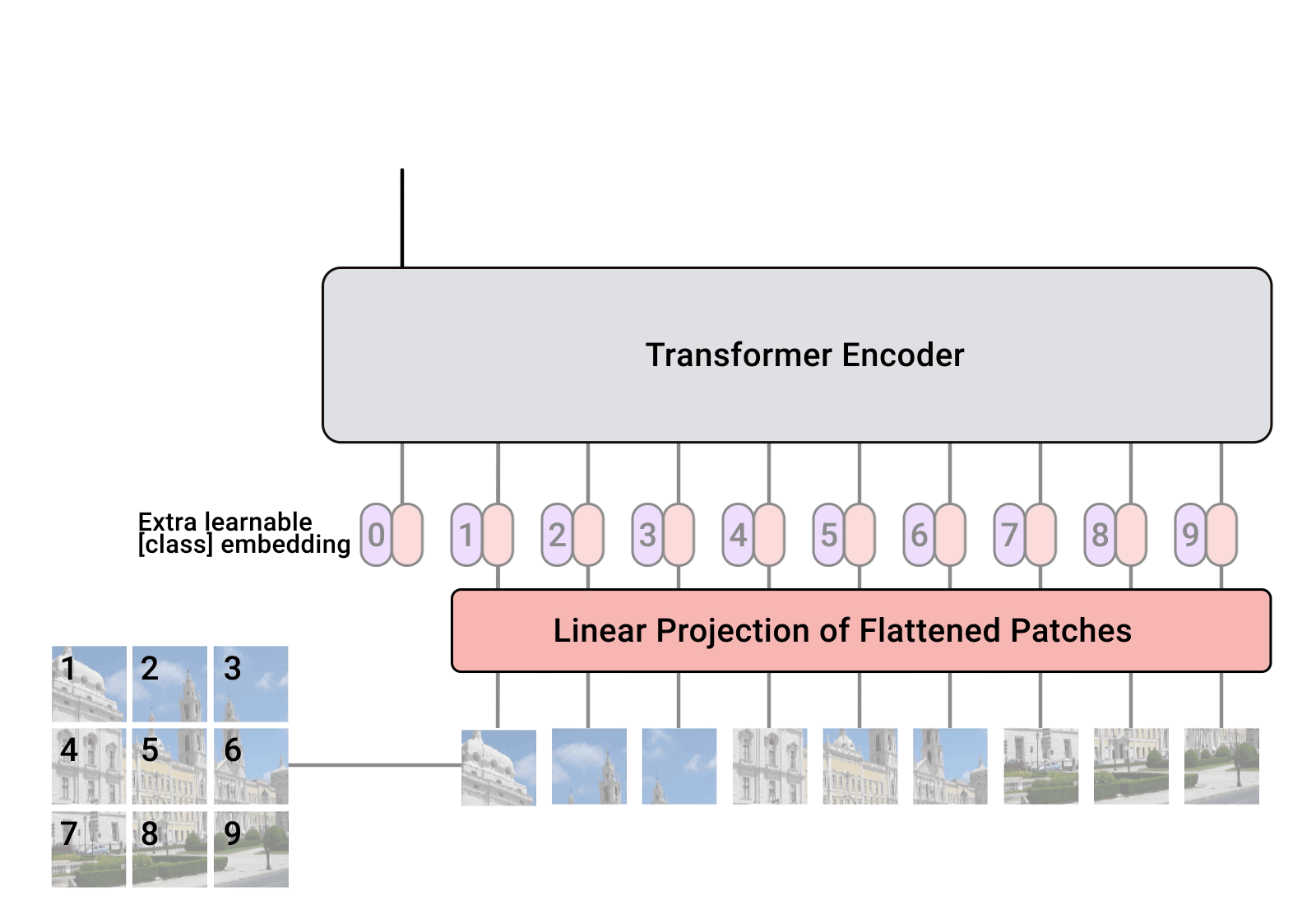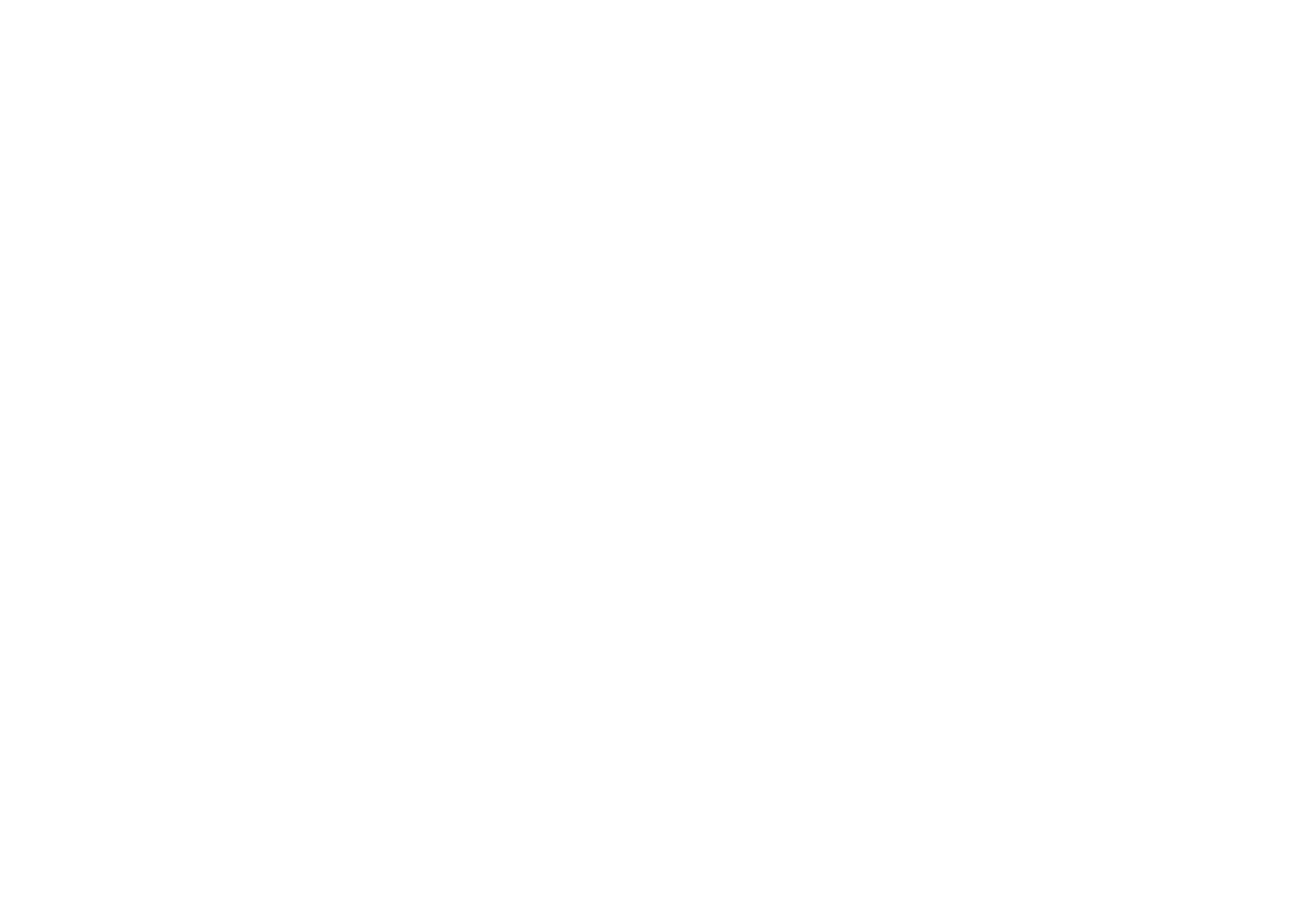
Vision Transformer. Credits
From the above figure, we observe that ViT divides an image into a grid of square patches. Each patch is flattened into a single vector by concatenating the channels of all pixels in a patch and then linearly projecting it to the desired input dimension. Because Transformers are agnostic to the structure of the input elements we add learnable position embeddings to each patch, which allow the model to learn about the structure of the images. A priori, ViT does not know about the relative location of patches in the image, or even that the image has a 2D structure — it must learn such relevant information from the training data and encode structural information in the position embeddings.
Working of Visual Transformer(ViT)
The overall working of the vision transformer model is given as follows in a step-by-step manner:
Image is first split into fixed-size patches.
The 2D image of size H *W is split into N patches where N=H*W/P²
If the image is of size 48 by 48 and the patch size is 16 by 16, then there will be 9 patches for the image.
The cost of self-attention is quadratic. If we pass each pixel of the image as input, then self-attention would require each pixel to attend to every other pixel. The quadratic cost of the self-attention will be very costly and not scale to realistic input size; hence, the image is divided into patches.
Flatten the 2D patches to 1D patch embedding and linearly embed them
Each patch is flattened into a 1D patch embedding by concatenating all pixel channels in a patch and then linearly projecting it to the desired input dimension.
Position embeddings are added to the patch embeddings to retain positional information.
Transformers are agnostic to the structure of the input elements. Adding the learnable position embeddings to each patch will allow the model to learn about the structure of the image.
We add an extra learnable “classification token” to the patch embedding at the start of the sequence.
This sequence of patch embedding vectors will be used as an input sequence length for the Transformer Encoder.

The Transformer Encoder consists of:
Multi-Head Self Attention Layer(MSP) to concatenate the multiple attention outputs linearly to expected dimensions. The multiple attention heads help learn local and global dependencies in the image.
Multi-Layer Perceptrons(MLP) contain two-layer with Gaussian Error Linear Unit(GELU)
Layer Norm(LN) is applied before every block as it does not introduce any new dependencies between the training images. Help improve the training time and generalization performance.
Residual connections are applied after every block as they allow the gradients to flow through the network directly without passing through non-linear activations.
For image classification, a classification head is implemented using MLP with one hidden layer at pre-training time and a single linear layer for fine-tuning.
The higher layers of ViT learn the global features, whereas the lower layers learn both global and local features. This allows ViT to learn more generic patterns.
ViT Pre-training and fine-tuning
ViT is pre-trained on large datasets and finetuned to a smaller dataset.
When fine-tuning, the last pre-trained prediction head is removed, and we attach a zero-initialized feed-forward layer to predict the classes based on the smaller dataset.
Fine-tuning can be applied to a higher resolution image than what the model was pre-trained on, but the patch size should remain the same.
Transformers has no prior knowledge about the image structure and hence have longer training times, and require large datasets for training the model.
While the ViT full-transformer architecture is a promising option for vision processing tasks, the performance of ViTs is still inferior to that of similar-sized CNN alternatives (such as ResNet) when trained from scratch on a mid-sized dataset such as ImageNet.

2021 Performance benchmark comparison of Vision Transformers (ViT) with ResNet and MobileNet when trained from scratch on ImageNet. – Credits
Why makes Vision Transformer (ViT) special?
This is not the first paper applying Transformer to Computer Vision. Facebook released Detection Transformers (DETR) in May 2020; however, DETR used Transformers in conjunction with CNN. ViT is the most successful application of Transformer for Computer Vision, and this research is considered to have made three contributions.
High Accuracy with Less Computation Time for Training
ViT has decreased the training time by 80% against Noisy Student (published by Google in Jun 2020) even though ViT has reached the approximately same accuracy as Table 2 on the paper (above) shows. Noisy Student adopted the EfficientNet architecture, and I will write another blog post about EfficientNet to help readers to see how far CNNs have traveled since ResNet in the near future.
Model Architecture without Convolutional Network
The core mechanism behind the Transformer architecture is Self-Attention. It gives the capability to understand the connection between inputs. When Transformers are applied for NLP, it computes the relation between words in a bi-directional manner, which means the order of input does not matter, unlike RNN. A model with Transformer architecture handles variable-sized input using stacks of Self-Attention layers instead of CNNs and RNNs. You can learn more about Transformer from here.
A major challenge of applying Transformers without CNN to images is applying Self-Attention between pixels. If the size of the input image is 640x640, the model needs to calculate self-attention for 409K combinations. Also, you can imagine that it is not likely that a pixel at a corner of an image will have a meaningful relationship with another pixel at the other corner of the image. ViT has overcome this problem by segmenting images into small patches (like 16x16). The atom of a sentence is a word, and this research defined a patch as the atom of an image instead of a pixel to efficiently tease out patterns.
Efficacy of Transformer with Small Patches
The paper has discovered that the model is able to encode the distance of patches in the similarity of position embeddings. Another discovery is that the paper found ViT integrates information across the entire image even in the lowest layers in Transformers. As a side-note, ViT-Large has 24 layers with a hidden size of 1,024 and 16 attention heads. The quote from the paper is “We find that some heads attend to most of the image already in the lowest layers, showing that the ability to integrate information globally is indeed used by the model.”
Analyzing the model performance qualitatively is often as important as analyzing quantitatively to understand the robustness of predictions. I usually use Class Activation Map (by MIT in 2015) to validate the robustness of model performance by reviewing class activation maps from the images with correct predictions, false positives, and false negatives to create and test different hypotheses.
Conclusion
The vision transformer model uses multi-head self-attention in Computer Vision without requiring image-specific biases. The model splits the images into a series of positional embedding patches, which are processed by the transformer encoder. It does so to understand the local and global features that the image possesses. Last but not least, the ViT has a higher precision rate on a large dataset with reduced training time.
Comments